Following on from my recent post about doing something this year, I’m committing to doing 12 months of “101”s; posts and projects themed at begining something new (or reasonably new) to me
January is all about node, and I started with a basic intro, then cracked open a basic web server with content-type manipulation and basic routing, created a basic API, before getting stuck into some great deployment and hosting solutions
Node Packages
Up until now I’ve been working with node using the basic code I’ve written myself. What about if you want to create an application that utilises websockets? Or how about a Sinatra-inspired web framework to shortcut the routing and request handling I’ve been writing? Maybe you want to have a really easy to build website without having to write HTML with a nice look without writing any CSS? Like coffeescript? mocha? You gaddit.
Thanks to the node package manager you can easily import pre-built packages into your project to do alllll of these things and loads more. This command line tool (which used to be separate but is now a part of the node install itself) can install the packages in a ruby gem-esque/.Net nuget fashion, pulling down all the dependencies automatically.
Example usage:
[code]npm install express -g[/code]
The packages (compiled C++ binaries, just like node itself) are pulled either into your working directory (local node_modules folder) or as a global package (with the “-g” parameter). You then reference the packages in your code using “requires”.
Or you can install everything your project needs at once by creating a package.json e.g.:
[code]{
"name": "basic-node-package",
"version": "0.0.1",
"dependencies": {
"express": "*",
"jade": "*",
"stylus": "*",
"nib": "*"
}
}[/code]
And then call [code]npm install[/code]
A great intro to using these four packages can be found on the clock website
I’ve decided to write a wrapper for my basic node API using express, jade, stylus, and nib. All I’m doing is call the api and displaying the results on a basic page. The HTML is being written in jade and the css in stylus & nib. Routing is being handled by express.
app.js
[js]var express = require(‘express’)
, stylus = require(‘stylus’)
, nib = require(‘nib’)
, proxy = require(‘./proxy’)
var app = express()
function compile(str, path) {
return stylus(str)
.set(‘filename’, path)
.use(nib())
}
app.set(‘views’, __dirname + ‘/views’)
app.set(‘view engine’, ‘jade’)
app.use(express.logger(‘dev’))
app.use(stylus.middleware(
{ src: __dirname + ‘/public’
, compile: compile
}
))
app.use(express.static(__dirname + ‘/public’))
var host = ‘rposbo-basic-node-api.azurewebsites.net’;
app.get(‘/products/:search/:key’, function (req,response) {
console.log("Request handler ‘products’ was called");
var requestPath = ‘/products/’ + req.params.search + ‘?key=’ + req.params.key;
proxy.getRemoteData(host, requestPath, function(json){
var data = JSON.parse(json);
response.render(‘products’,
{
title: ‘Products for’ + data.category,
products: data.products,
key: req.params.key
}
);
})
});
app.get(‘/product/:id/:key’, function (req,response) {
console.log("Request handler ‘product’ was called");
var requestPath = ‘/product/’ + req.params.id + ‘?key=’ + req.params.key;
proxy.getRemoteData(host, requestPath, function(json){
var data = JSON.parse(json);
response.render(‘product’,
{
title: data.title,
product: data
}
);
})
});
app.get(‘/’, function (req,response) {
console.log("Request handler ‘index’ was called");
response.end("Go");
});
app.listen(process.env.PORT);
[/js]
So that file sets up the express, jade, and stylus references and wires up the routes for /products/ and /product/ which then make a call using my old proxy.js to the API; I can probably do all of this with a basic inline http get, but I’m just reusing it for the time being.
Notice how the route “/products/:search/:key” which would actually be something like “/products/jeans/myAp1k3Y” is referenced using req.params.search and req.params.key.
Then all I’m doing is making the API call, parsing the returned JSON and passing that parsed object to the view.
The views are written in jade and have a main shared one:
layout.jade
[code]!!!5
html
head
title #{title}
link(rel=’stylesheet’, href=’/stylesheets/style.css’)
body
header
h1 basic-node-packages
.container
.main-content
block content
.sidebar
block sidebar
footer
p Running on node with Express, Jade and Stylus[/code]
Then the route-specific ones:
products.jade:
[code]extend layout
block content
p
each product in products
li
a(href=’/product/’ + product.id + ‘/’ + key)
img(src=product.image)
p
=product.title[/code]
and
product.jade:
[code]extend layout
block content
p
img(src=product.image)
li= product.title
li= product.price[/code]
The stylesheet is written in stylus & nib:
style.styl
[css]/*
* Import nib
*/
@import ‘nib’
/*
* Grab a custom font from Google
*/
@import url(‘http://fonts.googleapis.com/css?family=Quicksand’)
/*
* Nib provides a CSS reset
*/
global-reset()
/*
* Store the main color and
* background color as variables
*/
main-color = #fa5b4d
background-color = #faf9f0
body
font-family ‘Georgia’
background-color background-color
color #444
header
font-family ‘Quicksand’
padding 50px 10px
color #fff
font-size 25px
text-align center
/*
* Note the use of the `main-color`
* variable and the `darken` function
*/
background-color main-color
border-bottom 1px solid darken(main-color, 30%)
text-shadow 0px -1px 0px darken(main-color, 30%)
.container
margin 50px auto
overflow hidden
.main-content
float left
p
margin-bottom 20px
li
width:290
float:left
p
line-height 1.8
footer
margin 50px auto
border-top 1px dotted #ccc
padding-top 5px
font-size 13px[/css]
And this is compiled into browser-agnostic css upon compilation of the app.
The other files used:
proxy.js:
[js]var http = require(‘http’);
function getRemoteData(host, requestPath, callback){
var options = {
host: host,
port: 80,
path: requestPath
};
var buffer = ”;
var request = http.get(options, function(result){
result.setEncoding(‘utf8’);
result.on(‘data’, function(chunk){
buffer += chunk;
});
result.on(‘end’, function(){
callback(buffer);
});
});
request.on(‘error’, function(e){console.log(‘error from proxy call: ‘ + e.message)});
request.end();
};
exports.getRemoteData = getRemoteData;[/js]
package.json
[js]{
"name": "basic-node-package",
"version": "0.0.1",
"dependencies": {
"express": "*",
"jade": "*",
"stylus": "*",
"nib": "*"
}
}[/js]
web.config
[xml]<configuration>
<system.web>
<compilation batch="false" />
</system.web>
<system.webServer>
<handlers>
<add name="iisnode" path="app.js" verb="*" modules="iisnode" />
</handlers>
<iisnode loggingEnabled="false" />
<rewrite>
<rules>
<rule name="myapp">
<match url="/*" />
<action type="Rewrite" url="app.js" />
</rule>
</rules>
</rewrite>
</system.webServer>
</configuration>[/xml]
All of these files are, as usual, on Github
Deployment with Packages
Something worth bearing in mind is that deploying something which includes packages and the result of packages (e.g. minified js or css from styl) requires all of these artifacts to be added into your git repo before deployment to certain hosts such as Appharbor and Azure; Heroku will actually run an npm install as part of the deployment step, I believe, and also compile the .styl into .css, unlike Azure/Appharbor.
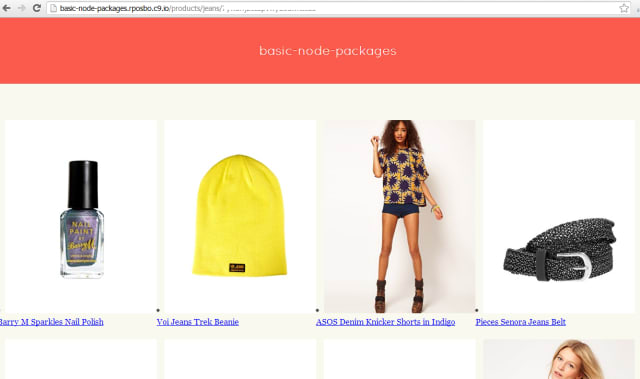
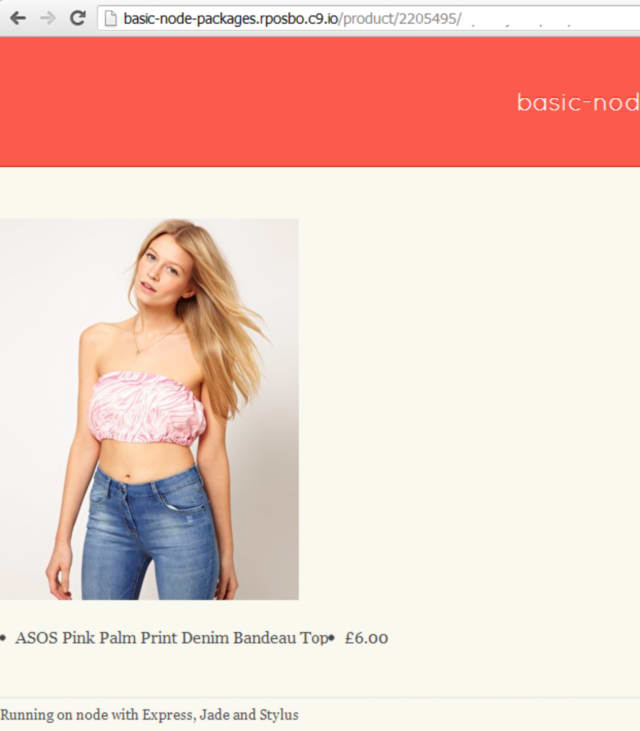
The files above give a very basic web interface to the /products/ and /product/ routes:
Coming up
Web-based node development and deployment!