The wonderful people at Transport For London (TFL) recently released (but didn’t seem to publicise) a new page on their site that would give you a countdown listing of buses due to arrive at any given stop in London.
This is the physical one (which only appears on some bus stops):

And this is the website one, as found at countdown.tfl.gov.uk

Before I continue with the technical blithering, I’d like quantify how useful this information is by way of a use case: you’re in a pub/bar/club, a little worse for wear, the tubes have stopped running, no cash for a cab, it’s raining, no jacket. You can see a bus stop from a window, but you’ve no idea how long you’d have to wait in the rain before your cheap ride home arrived. IF ONLY this information were freely available online so you can check if you have time for another drink/comfort break/say your goodbyes before a short stroll to hail the arriving transport.
With this in mind I decided to create a mobile friendly version of the page.
If you visit the tfl site (above) and fire up fiddler you can see that the request for stops near you hits one webservice which returns json data,

and then when you select a stop there’s another call to another endpoint which returns json data for the buses due at that stop:

Seems easy enough. However, the structure of the requests which follow on from a search for, say, the postcode starting with “W6” is a bit tricky:
http://countdown.tfl.gov.uk/markers/
swLat/51.481382896100975/
swLng/-0.263671875/
neLat/51.50874245880333/
neLng/-0.2197265625/
?_dc=1315778608026
That doesn’t say something easy like “the postcode W6”, does it? It says “these exact coordinates on the planet Earth”.
So how do I emulate that? Enter JAVASCRIPT’S NAVIGATOR.GEOLOCATION!
Have you ever visited a page or opened an app on your phone and saw a popup asking for your permission to share your location with the page/app? Something like:
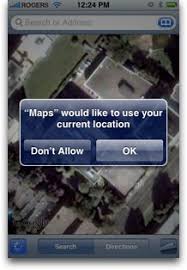
Or in your browser:

This is quite possibly the app attempting to utilise the javascript geolocation API in order to try and work out your latitude and longitudinal position.
This information can be easily accessed by browsers which support the javascript navigator.geolocation API. Even though the API spec is only a year old, diveintohtml5 point out it’s actually currently supported on quite a few browsers, including the main mobile ones.
The lat and long can be gleaned from the method
[javascript]
navigator
.geolocation
.getCurrentPosition
[/javascript]
which just takes a callback function as a parameter passing a “position” object e.g.
[javascript]
navigator
.geolocation
.getCurrentPosition(showMap);
function show_map(position) {
var latitude = position.coords.latitude;
var longitude = position.coords.longitude;
// let’s show a map or do something interesting!
}
[/javascript]
Using something similar to this we can pad the single position to create a small area instead, which we pass to the first endpoint, retrieve a listing of bus stops within that area, allow the user to select one, pass that stop ID as a parameter to the second endpoint to retrieve a list of the buses due at that stop, and display them to the user.
My implementation is:
[javascript]
$(document).ready(function() {
// get lat long
if (navigator.geolocation){
navigator
.geolocation
.getCurrentPosition(function (position) {
getStopListingForLocation(
position.coords.latitude,
position.coords.longitude);
});
} else {
alert(‘could not get your location’);
}
});
[/javascript]
Where getStopListingForLocation is just
[javascript]
function getStopListingForLocation(lat, lng){
var swLat, swLng, neLat, neLng;
swLat = lat – 0.01;
swLng = lng – 0.01;
neLat = lat + 0.01;
neLng = lng + 0.01;
var endpoint =
‘http://countdown.tfl.gov.uk/markers’ +
‘/swLat/’ + swLat +
‘/swLng/’ + swLng +
‘/neLat/’ + neLat +
‘/neLng/’ + neLng + ‘/’;
$.ajax({
type: ‘POST’,
url: ‘Proxy.asmx/getMeTheDataFrom’,
data: "{‘here’:’"+endpoint+"’}",
contentType: "application/json; charset=utf-8",
dataType: "json",
success: function(data) {
displayStopListing(data.d);
}
});
}
[/javascript]
The only bit that had me confused for a while was forgetting that browsers don’t like cross browser ajax requests. The data will be returned and is visible in fiddler, but the javascript (or jQuery in my case) will give a very helpful “error” error.
As such, I created the World’s Simplest Proxy:
[csharp]
[System.Web.Script.Services.ScriptService]
public class Proxy: System.Web.Services.WebService
{
[WebMethod]
public string getMeTheDataFrom(string here)
{
using (var response = new System.Net.WebClient())
{
return response.DownloadString(here);
}
}
}
[/csharp]
All this does, quite obviously, is to forward a request and pass back the response, running on the server – where cross domain requests are just peachy.
Then I have a function to render the json response
[javascript]
function displayStopListing(stopListingData){
var data = $.parseJSON(stopListingData);
$.each(data.markers, function(i,item){
$("<li/>")
.text(item.name + ‘ (stop ‘ + item.stopIndicator + ‘) to ‘ + item.towards)
.attr("onclick", "getBusListingForStop(" + item.id + ")")
.attr("class", "stopListing")
.attr("id", item.id)
.appendTo("#stopListing");
});
}
[/javascript]
And then retrieve and display the bus listing
[javascript]
function getBusListingForStop(stopId){
var endpoint = ‘http://countdown.tfl.gov.uk/stopBoard/’ + stopId + ‘/’;
$("#" + stopId).attr("onclick","");
$.ajax({
type: ‘POST’,
url: ‘Proxy.asmx/getMeTheDataFrom’,
data: "{‘here’:’"+endpoint+"’}",
contentType: "application/json; charset=utf-8",
dataType: "json",
success: function(data) { displayBusListing(data.d, stopId); }
});
}
function displayBusListing(busListingData, stopId){
var data = $.parseJSON(busListingData);
$("<h2 />").text("Buses Due").appendTo("#" + stopId);
$.each(data.arrivals, function(i,item){
$("<span/>")
.text(item.estimatedWait)
.attr("class", "busListing time")
.appendTo("#" + stopId);
$("<span/>")
.text(item.routeName + ‘ to ‘ + item.destination)
.attr("class", "busListing info")
.appendTo("#" + stopId);
$("<br/>")
.appendTo("#" + stopId);
});
}
[/javascript]
(yes, my jQuery is pants. I’m working on it..)
These just need some very basic HTML to hold the output
[html]
<h1>Bus Stops Near You (tap one)</h1>
<ul id="stopListing"></ul>
[/html]
Which ends up looking like

The resultingfull HTML can be found here, the Most Basic Proxy Ever is basically listed above, but also in “full” here. If you want to see this in action head over to rposbo.apphb.com.
Next up – how this little page was pushed into the cloud in a few seconds with the wonder of AppHarbor and git.
UPDATE
Since creation of this “app” TFL have created a very nice mobile version of their own which is much nicer than my attempt! Bookmark it at m.countdown.tfl.gov.uk :