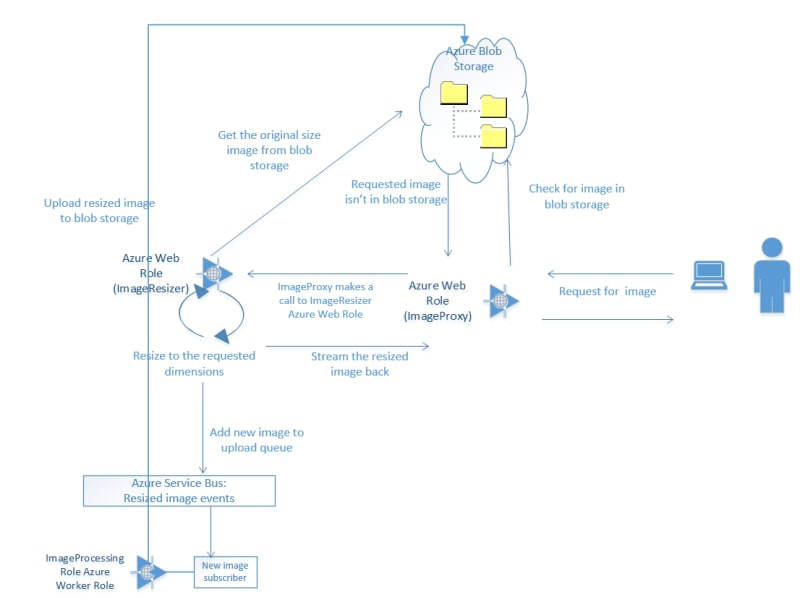
The previous couple of articles configured an image resizing Azure Web Role, plopped those resized images on an Azure Service Bus, picked them up with a Worker Role and saved them into Blob Storage.
This one will click in the last missing piece; the proxy at the front to initially attempt to get the pregenerated image from blob storage and failover to requesting a dynamically resized image.
New Web Role
Add a new web role to your cloud project – I’ve called mine “ImagesProxy” – and make it an empty MVC4 Web API project. This is the easiest of the projects, so you can just crack right on and create a new controller – I called mine “Image” (not the best name, but it’ll do).
Retrieve
This whole project will consist of one controller with one action – Retrieve – which does three things;
- attempt to retrieve the resized image directly from blob storage
- if that fails, go and have it dynamically resized
- if that fails, send a 404 image and the correct http header
Your main method/action should look something like this:
[csharp][HttpGet]
public HttpResponseMessage Retrieve(int height, int width, string source)
{
try
{
var resizedFilename = BuildResizedFilenameFromParams(height, width, source);
var imageBytes = GetFromCdn("resized", resizedFilename);
return BuildImageResponse(imageBytes, "CDN", false);
}
catch (StorageException)
{
try
{
var imageBytes = RequestResizedImage(height, width, source);
return BuildImageResponse(imageBytes, "Resizer", false);
}
catch (WebException)
{
var imageBytes = GetFromCdn("origin", "404.jpg");
return BuildImageResponse(imageBytes, "CDN-Error", true);
}
}
}
[/csharp]
Feel free to alt-enter and clean up the red squiggles by creating stubs and referencing the necessary assemblies.
You should be able to see the three sections mentioned above within the nested try-catch blocks.
-
attempt to retrieve the resized image directly from blob storage
[csharp]var resizedFilename = BuildResizedFilenameFromParams(height, width, source);
var imageBytes = GetFromCdn("resized", resizedFilename);
return BuildImageResponse(imageBytes, "CDN", false);
[/csharp] -
if that fails, go and have it dynamically resized
[csharp]var imageBytes = RequestResizedImage(height, width, source);
return BuildImageResponse(imageBytes, "Resizer", false)
[/csharp] -
if that fails, send a 404 image and the correct http header
[csharp]var imageBytes = GetFromCdn("origin", "404.jpg");
return BuildImageResponse(imageBytes, "CDN-Error", true);
[/csharp]
So let’s build up those stubs.
BuildResizedFilenameFromParams
Just a little duplication of code to get the common name of the resized image (yes, yes, this logic should have been abstracted out into a common library for all projects to reference, I know, I know..)
[csharp]private static string BuildResizedFilenameFromParams(int height, int width, string source)
{
return string.Format("{0}_{1}-{2}", height, width, source.Replace("/", string.Empty));
}
[/csharp]
GetFromCDN
We’ve seen this one before too; just connecting into blob storage (within these projects blob storage is synonymous with CDN) to pull out the pregenerated/pre-reseized image:
[csharp]private static byte[] GetFromCdn(string path, string filename)
{
var connectionString = CloudConfigurationManager.GetSetting("Microsoft.Storage.ConnectionString");
var account = CloudStorageAccount.Parse(connectionString);
var cloudBlobClient = account.CreateCloudBlobClient();
var cloudBlobContainer = cloudBlobClient.GetContainerReference(path);
var blob = cloudBlobContainer.GetBlockBlobReference(filename);
var m = new MemoryStream();
blob.DownloadToStream(m);
return m.ToArray();
}
[/csharp]
BuildImageResponse
Yes, yes, I know – more duplication.. almost. The method to create an HTTP response message from before, but this time with extras params to set a header saying where the image came from, and allow to set the HTTP status code correctly. We’re just taking the image bytes and putting them in the message content, whilst setting the headers and status code appropriately.
[csharp]private static HttpResponseMessage BuildImageResponse(byte[] imageBytes, string whereFrom, bool error)
{
var httpResponseMessage = new HttpResponseMessage { Content = new ByteArrayContent(imageBytes) };
httpResponseMessage.Content.Headers.ContentType = new MediaTypeHeaderValue("image/jpeg");
httpResponseMessage.Content.Headers.Add("WhereFrom", whereFrom);
httpResponseMessage.StatusCode = error ? HttpStatusCode.NotFound : HttpStatusCode.OK;
return httpResponseMessage;
}
[/csharp]
RequestResizedImage
Build up a request to our pre-existing image resizing service via a cloud config setting and the necessary dimensions and filename, and return the response:
[csharp]private static byte[] RequestResizedImage(int height, int width, string source)
{
byte[] imageBytes;
using (var wc = new WebClient())
{
imageBytes = wc.DownloadData(
string.Format("{0}?height={1}&width={2}&source={3}",
CloudConfigurationManager.GetSetting("Resizer_Endpoint"),
height, width, source));
}
return imageBytes;
}
[/csharp]
And that’s all there is to it! A couple of other changes to make within your project in order to allow pretty URLs:
-
Create the necessary route:
[csharp]config.Routes.MapHttpRoute(
name: "Retrieve",
routeTemplate: "{height}/{width}/{source}",
defaults: new { controller = "Image", action = "Retrieve" }
);
[/csharp] -
Be a moron:
[xml] <system.webServer>
<modules runAllManagedModulesForAllRequests="true" />
</system.webServer>
[/xml]
That last one is dangerous; I’m using it here as a quick hack to ensure that URLs ending with known file extensions (e.g., /600/200/image1.jpg) are still processed by the MVC app instead of assuming they’re static files on the filesystem. However, this setting is not advised since it means that every request will be picked up by your .Net app; don’t use it in regular web apps which also host images, js, css, etc!
If you don’t use this setting then you’ll go crazy trying to debug your routes, wondering why nothing is being hit even after you install Glimpse..
In action
First request
Hit your proxy with a request for an image that exists within your blob storage “origin” folder; this will raise a storage exception when attempting to retrieve from blob storage and drop into the resizer code chunk e.g.:

Notice the new HTTP header that tells us the request was fulfilled via the Resizer service, and we got an HTTP 200 status code. The resizer web role will have also added a message to the service bus awaiting pick up.
Second request
By the time you refresh that page (if you’re not too trigger happy) the uploader worker role should have picked up the message from the service bus and saved the image data into blob storage, such that subsequent requests should end up with a response similar to:

Notice the HTTP header tells us the request was fulfilled straight from blob storage (CDN), and the request was successful (HTTP 200 response code).
Failed request
If we request an image that doesn’t exist within the “origin” folder, then execution drops into the final code chunk where we return a default image and set an error status code:

So..
This is the last bit of the original plan:
Please grab the source from github, add in your own settings to the cloud config files, and have a go. It’s pretty cool being able to just upload one image and have other dimension images autogenerated upon demand!







